
Abstract
Traditional speech emotion recognition (SER) evaluations have been performed merely on a speaker-independent (SI) condition; some of them even did not evaluate their result on this condition (speaker-dependent, SD). This paper highlights the importance of splitting training and test data for SER by script, known as sentence-open or text-independent (TI) criteria. The results show that employing sentence-open criteria degraded the performance of SER. This finding implies the difficulties of recognizing emotion from speech in different linguistic information embedded in acoustic information. Surprisingly, text-independent criteria consistently performed worse than speaker+text-independent (STI) criteria. The full order of difficulties for splitting criteria on SER performances from the most difficult to the easiest is text- independent, speaker+text-independent, speaker-independent, and speaker+text-dependent. The gap between speaker+text- independent and text-independent was smaller than other criteria, strengthening the difficulties of recognizing emotion from speech in different sentences.
Method
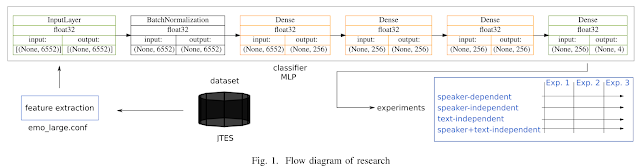
Experiment #2: 5-fold cross-validation
Experiment #3: Same number of training and test data
Result
 |
Take home message
Sentence (or linguistic) information plays a crucial role in speech emotion recognition.
