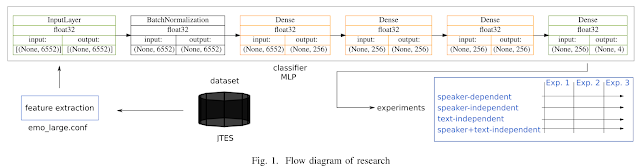
Kode di bawah ini mengekstrak tiga fitur akustik -- spectrogram, melspectrogram, dan mfcc -- dari sebuah file audio "filename" (wav, mp3, ogg, flacc, dll). Ketiga fitur akustik tersebut merupakan fitur-fitur akustik terpenting dalam pemrosesan sinyal wicara. Keterangan singkat ada di dalam badan kode. Hasil plot ada di bawah kode.
###
#import torch
import torchaudio
from matplotlib import pyplot as plt
import librosa
# show torchaudio version
# torch.__version__
print(torchaudio.__version__)
def plot_spectrogram(spec, title=None, ylabel="freq_bin", aspect="auto",
xmax=None):
fig, axs = plt.subplots(1, 1)
axs.set_title(title or "Spectrogram (db)")
axs.set_ylabel(ylabel)
axs.set_xlabel("frame")
im = axs.imshow(librosa.power_to_db(spec), origin="lower", aspect=aspect)
if xmax:
axs.set_xlim((0, xmax))
fig.colorbar(im, ax=axs)
plt.show(block=False)
filename = "/home/bagus/train_001.wav" # change with your file
waveform, sample_rate = torchaudio.load(filename)
# Konfigurasi untuk spectrogam, melspectrogram, dan MFCC
n_fft = 1024
win_length = None # jika None maka sama dengan n_fft
hop_length = 512 # y-axis in spec plot
n_mels = 64 # y-axis in melspec plot
fmin = 50
fmax = 8000
n_mfcc = 40 # must be smaller than n_mels, will be y-axis in plot
# definisi kelas untuk ekstraksi spektrogram
spectrogram = torchaudio.transforms.Spectrogram(
n_fft=n_fft,
win_length=win_length,
hop_length=hop_length,
center=True,
pad_mode="reflect",
power=2.0,
)
# Show plot of spectrogram
spec = spectrogram(waveform)
print(spec.shape) # torch.Size([1, 513, 426])
plot_spectrogram(spec[0], title=f"Spectrogram - {str(filename)}")
## kelas untuk ekstraksi melspectrogram
melspectogtram = torchaudio.transforms.MelSpectrogram(
sample_rate=sample_rate,
n_fft=n_fft,
win_length=win_length,
hop_length=hop_length,
n_mels=n_mels,
f_min=fmin,
f_max=fmax,
)
# Calculate melspec
melspec = melspectogtram(waveform)
melspec.shape # torch.Size([1, 513, 426])
plot_spectrogram(melspec[0], title=f"Melspectrogam - {str(filename)}")
## kelas untuk ekstraksi MFCC
mfcc_transform = torchaudio.transforms.MFCC(
sample_rate=sample_rate,
n_mfcc=n_mfcc,
melkwargs={
'n_fft': n_fft,
'n_mels': n_mels,
'hop_length': hop_length,
'mel_scale': 'htk',
}
)
# plot mfcc
mfcc = mfcc_transform(waveform)
print(mfcc.shape) # torch.Size([1, 40, 426])
plot_spectrogram(mfcc[0], title=f"MFCC - {str(filename)}")
###
Plot